Vorher-nachher Studie mit zwei Gruppen in Excel
In einer Studien- oder Bachelorarbeit haben Sie folgende Fragestellung bearbeitet:
Mit physiotherapeutischer Behandlung soll die Kraft im Armmuskel wiederhergestellt werden. Dazu wird bei bei der Eingangsvisite (Visite 0) die Hebekraft mit einer Federwaage gemessen; nach drei Wochen Behandlung wird bei Visite 1 die Kraft noch einmal gemessen. Die 20 Patienten sind randomisiert auf zwei Behandlungsgruppen verteilt, die mit den alternativen Methoden (treatment) a und b behandelt werden.
An diesem Beispiel wird gezeigt, wie Sie die Daten auswerten und das Ergebnis beschreiben können. Sie können die Methode analog in vielen anderen Studien verwenden, bei denen die Änderung eines Messwertes durch Behandlung ermittelt wird, und zwei Methoden oder Placebo/Verum zur Anwendung kommen.
Dateneingabe
Eine Anleitung zur Dateneingabe mit Excel finden Sie hier. Auf dem Arbeitsblatt mit den Daten haben Sie sicherlich viele Messwerte von anderen Muskeln oder von weiteren Visiten zusammengestellt; das ist sinnvoll, alle Primärdaten sollten auf einer Seite stehen. Zur Auswertung sollten Sie aber die Spalten, die Sie benötigen, auf eine eigene Seite kopieren; oder noch besser durch einen Link mit der Hauptseite verknüpfen.
Auf einem neuen Excel-Arbeitsblatt, dem Sie einen aussagekräftigen Namen geben (nicht Tabelle1), legen Sie Verknüpfungen zu folgenden Daten an. Beachten Sie dabei, dass die Überschriften auch verknüpft werden und dass diese in Zeile 1 stehen.
patid: Patienten-IDtreatment: a oder b; diese müssen nicht sortiert sein, sondern können in beliebiger Reihenfolge auftretenforce_0: Die Kraft bei der Eingangsuntersuchungforce_1: Die Kraft nach dem ersten Behandlungsabschnittforce_diff: Die Differenz zwischenforce_1 - force_0; ein positiver Wert bedeutet also, dass sich die Hebekraft durch die Behandlung erhöht hat. Die Daten in dieser Spalte werden nicht von der Datenseite gelinkt, sondern mit einer Formel erzeugt, etwa= d1-c1.
Wandeln Sie jetzt den Datenbereich in eine echte Tabelle um; wählen Sie dazu die Daten an, und danach “als Tabelle formatieren” im Menü. Dieser Schritt ist nicht nötig, erspart Ihnen aber viel Ärger.

Gehen Sie jetzt mit dem Cursor auf die Überschrift treatment und klicken Sie auf Sortieren/Von A bis Z sortieren; das funktioniert nur dann so einfach, wenn Sie den Bereich als echte Tabelle formatiert haben, wenn Sie das vergessen haben, müssen Sie sich noch einige weitere Fragen gefallen lassen, und können Fehler machen.
Jetzt sind alle Behandlungen a oben und alle b unten angeordnet, die Daten sollten also so aussehen.

Im blauen Rahmen sind die Daten, sortiert nach Behandlung, und in Spalte E die mit Formel erzeugte Differenz. Sie können das auch live auf Seite vn in der Exceldatei anschauen. Es kann sein, dass Ihre Tabelle andere Farben hat, das macht nichts, Farben können Sie bei der Umwandlung in eine Tabelle beliebig auswählen.
Bei dieser Studie waren 10 Patienten je Behandlungsgruppe geplant, aber einer der Gruppe b (P20) ist als ausgefallen simuliert, drum sind es insgesamt nur 19 Patienten.
Graphik
Von allen Ihren Daten sollten Sie eine Grafik erstellen; Fehler erkennt man daran am leichtesten, und wichtige Grafiken können Sie in die Arbeit übernehmen - das schindet Seiten. Bei vorher-nachher Vergleichen ist ein Punktdiagramm (Scatterplot) sinnvoll. Auf der x-Achse tragen Sie dazu die Werte von Visite 0 (= vorher) auf, auf der y-Achse die Werte von Visite 1, und Farben verwenden Sie, um die beiden Gruppen zu unterscheiden. Das sieht im Ergebnis so aus:


Es ist nicht ganz einfach, die Graphik in Excel zu erzeugen, und leider verhält sich jeder Excel-Version etwas anders. Suchen Sie im Internet nach “scatterplot excel”, oder verwenden Sie die Excel-Hilfe. Beachten Sie folgendes:
- Tragen Sie zwei Datenreihen in die Grafik ein, eine für Treatment a und eine für Treatement b. Dazu müssen die Daten durch Sortieren geordnet sein, dass alle a und b im Datenblock zusammen stehen.
- Wählen Sie die Achsen von Hand, aber so, dass beide Achsen den gleichen Bereich anzeigen. Ändern Sie die Bildgröße so, dass der Kasten mit den Datenpunkten etwa quadratisch ist.
- Wählen sie ein Hintergrund-Gitter mit nicht allzu vielen Gitterlinien; 1 bis 3 reichen.
- Fügen Sie von Hand Beschriftungen für die Achsen hinzu, die immer die Maßeinheit enthalten sollen, etwa “Kraft bei Visite 1 (kp)”.
- Geben Sie den Text für die Legende als Reihenname in die Box Datenreihe bearbeiten ein; siehe rechts im Bild.
- Wenn Sie es schön machen wollen, fügen Sie noch die Winkelhalbierende in den Plot ein, indem Sie eine neue Datenreihe mit (10,10) kg und (20,20) kg einfügen.
Aus diesem Plot kann man lesen: * Daten oberhalb der Winkelhalbierenden bedeuten eine Verbesserung durch die Behandlung; nur vier Punkte (P04, P16, P17, P19) liegen unterhalb der Winkelhalbierenden. Je weiter weg von der Winkelhalbierenden, desto größer der Effekt. * Die Wolke der Daten ist dicht, was darauf hinweist, das keine Ausreißer drin sind. In der beiliegenden Exceldatei habe ich aber einen hineingeschmuggelt. Finden Sie ihn. * Die blauen Punkte liegen weiter weg von der Winkelhalbierenden, deshalb kann man vermuten, dass man mit Behandlung a eine größere Verbesserung der Muskelstärke erreichen kann.
Fragestellungen, erste Annäherung
Folgende Fragestellungen können Sie versuchen zu beantworten:
- Hilft “dem” Patienten die Behandlung a? Dies Fragestellung lässt sich mit einem Blick beantworten, das Ergebnis ist aber nicht sehr hilfreich: Bei allen Patienten mit Ausnahme von P04 ist die Armkraft nach der Behandlung höher, denn die nachher-vorher Differenz ist nur bei P04 negativ. Hat das System, oder ist es die Laune des Zufalls? Wer jetzt Vorzeichentest denkt, darf vorrücken auf das nächste Kapitel.
- Hilft Behandlung a der Mehrheit der Patienten? Diese Fragestellung ist zwar medizinisch einleuchtend, aber was heißt “die Mehrheit”? 50.01%? Oder sind die 50.01% in Wirklichkeit nur 49.9%? Und reicht diese Verbesserung aus, um die Behandlung ethisch und ökonomisch zu rechtfertigen? Um das sicher zu wissen, müssten wir alle Menschen mit Programm a behandeln; das geht jedoch nicht, wir haben nur eine Stichprobe, noch dazu eine ziemlich kleine. Aus dieser Stichprobe wollen wir auf die Gesamtheit aller zukünftigen Patienten schließen, und das ist ungenau.
- Nächster Anlauf: Da wir nur eine Stichprobe haben, kann der Anteil der Patienten, denen die Behandlung helfen würde, nur als Bereich angegeben werden kann. Wir können vielleicht sagen, dass mit 95% Wahrscheinlichkeit die Behandlung mindestens 60% aller Patienten hilft, und höchstens 80%. Was heißt 95% Wahrscheinlichkeit? Wenn wir die gesamte Studie (die Studie mit 2x10 Patienten) 1000 mal wiederholen würden, würden in etwa 25 Studien (Studien, nicht Patienten) die Behandlung bei weniger als 6 der 10 Patienten erfolgreich sein.
- Mediziner denken oft in dieser Kategorie “Wie vielen Patienten hilft die Behandlung”, und man kann sie mit der im vorigen Abschnitte beschriebenen Methode beantworten. In der Epidemiologie, wo man oft Tausende Patienten hat, kann dieses Vorgehen, also die Reduktion auf Erfolg/kein Erfolg sinnvoll sein. In einer randomisierten Studie werden aber nur wenige Patienten eingeschlossen, deshalb kann der Bereich nur geschätzt werden. Warum? Weil wir die Daten vorher auf eine ja/nein-Alternative oder Erfolg/kein Erfolg oder positive Differenz/negative Differenz reduziert haben, dabei geht Information verloren. Statistisch gesehen wenden wir dabei den Vorzeichentest auf die Daten an; der Vorzeichentest ist robust, extreme Verbesserungen werden dabei gleich behandelt wie winzige.
- Bei geplanten Studien bekommt man mit wenig Daten schärfere Ergebnisse (= mehr Power), wenn man die Fragestellung folgendermaßen abändert: Um wie viel Kilopond vergrößert sich die Hebekraft durch die Behandlung mindestens? Genauer formuliert: Um wie viele Kilopond vergrößert sich die Hebekraft bei 97.5% der Patienten mindestens? Diese Aussage ist genauer als die schlichte Zählstatistik, und es lässt sich auch die Frage “lohnt sich der Aufwand für den Patienten” in Kilopond ausdrücken: eine Verbesserung von 15 auf 20 ist es wert, eine von 15 auf 16 vermutlich nicht, auch wenn sie noch so sicher nachgewiesen werden kann.
- Wer unbedingt will oder muss, weil der Chef oder Prof es befiehlt, kann damit auch den p-Wert berechnen; seine Interpretation sei hier nicht besprochen, bestimmt ist das Ding in Vorlesungen bis zum Ermüdungsbruch behandelt worden. Wie sehr viele Statistiker halte ich p-Werte für überstrapaziert, denn damit wird eine differenzierte Aussage mit inhaltlicher Bedeutung (“5 Kilopond Verbesserung mindestens”) auf eine ja-nein-Aussage oder eine sehr kapriziöse Wahrscheinlichkeit zu reduziert; auch wenn Sie sehr wenig Zeit haben, sollten Sie sich den Youtube-Film ab Minute 5 anschauen. Wer es genauer wissen will: es gibt eine offizielle Stellungnahme der Amerikanischen Statistischen Gesellschaft zum Missbrauch von p-Werten. In meinem Web-basierten Programm zur Berechnung paarweiser Wilcoxon-Tests, nicht mehr online werden deshalb Vertrauensbereiche angegeben, die leicht zu berechnenden p-Werte aber nicht - it’s a feature, not a bug.
Fragestellungen, zweiter Versuch
- Ist die mittlere Änderung der Kraft durch die Behandlung a positiv? Was ist die minimale Verbesserung, die mit wahrscheinlich nicht unterschritten wird? Die minimale Verbesserung ist gegeben durch den unteren Wert des Konfidenzintervalls der Differenzen.
- Ist die mittlere Änderung der Kraft durch die Behandlung b positiv? Der Rest wie bei 1.
- Gibt es einen Unterschied zwischen den beiden Behandlungen? Ist die Verbesserung bei Behandlung a größer oder kleiner als bei Behandlung b? Dazu wird das Konfidenzintervall der Differenz der Verbesserungen zwischen den beiden Behandlungen bestimmt.
Sind Sie bei letzten Satz ausgestiegen? Vielleicht wird es bei der praktischen Durchführung klarer.
Die Fragestellungen 1. und 2. werden dabei jeweils innerhalb eines Patienten bestimmt (“within-patient”); die Kraft bei jedem Patienten wird zweimal gemessen. Dies bedeutet, dass Sie einen gepaarten Test verwenden. Bei der Fragestellung 3 werden zwar die vorher-nachher Differenzen innerhalb eines Patienten als Ausgangsmaterial verwendet, der eigentliche Vergleich wird aber zwischen verschiedenen Patienten vorgenommen (“between-patient”). Sie werden dazu also einen ungepaarten Test verwenden.

Reverend Bayes legt Einspruch ein, drum muss ich mich korrigieren: Sie werden häufig lesen, dass das 95%-Vertrauensintervall (“confidence interval”, CI) den Bereich angibt, in dem die Verbesserung mit 95% Wahrscheinlichkeit liegt. Diese Aussage stimmt leider nicht ganz, auch wenn sie so in vielen Büchern zu finden ist, und auch in der Microsoft-Dokumentation der hier verwendeten Funktionen. Bayessche Statistik erklärt die richtige Interpretation; der Bereich, in dem der Mittelwerte mit 95% Wahrscheinlichkeit liegt, ist das “credible interval” - eine deutsche Übersetzung hat sich nicht durchgesetzt. In der englischen Wikipedia gibt es eine Beschreibung des “credible interval”, in der deutschen nicht.
Für randomisierte geplante Studien wie der hier beschriebenen ist die Aussage aber näherungsweise richtig:
Der Mittelwert liegt mit 95% Wahrscheinlichkeit innerhalb der Vertrauensbereiches.
Welches ist die wichtigere Fragestellung? 1 und 2, oder 3? Für den einzelnen Patienten steht die Verbesserung bei sich selbst im Vordergrund. In der Medizin muss man solchen Verbesserungen misstrauen, sie könnten auch ein ein Placebo-Effekt sein, bedingt dadurch, dass sich überhaupt jemand um den Patienten kümmert. Vielleicht hätte auch eine Gesprächstherapie, ein Kaffeekränzchen oder die Behandlung des falschen Arms geholfen? Deshalb wird die Antwort auf die Frage 3 höher bewertet, weil der Placebo-Anteil in beiden Fällen ähnlich ist. In der Königsklasse der Studien würde man die eigentliche Behandlung noch verblinden - das geht aber beim physiotherapeutischen Interventionen nicht, ohne den Patienten und Physiotherapeuten einer Gehirnwäsche zu unterziehen.
Die Antworten auf Frage 3 sind wichtig, um vergleichende Aussagen über Behandlungen zu erzielen. Gönnen Sie also in Ihrer Arbeit der Antwort auf Frage 3 mehr Platz; meist ist der “primary Endpoint” einer Studie vom Typ Frage 3.
Schluss der Theorie - Excel muss ran
Falls Sie Ihre Daten in Excel haben, aber keine Lust, umständlich zu rechnen: Hier kommen Sie zur App.

Die App hat ein Manko, das ein diabolisches Feature ist: obwohl p-Werte leicht zu berechnen wären, werden diese nicht ausgegeben. Wenn also Ihr Boss oder Betreuer der Arbeit auf p-Werten besteht, muss er umdenken oder ein anderes Tool zur Verfügung stellen.
Veränderung der Kraft bei Methode a
Wenn bei Ihnen in Excel die Schaltfläche Datenanalyse auf dem Reiter Daten auftaucht, oder wenn sie diese wie hier beschrieben aktiviert haben, können Sie die dort vorhandenen rudimentären Statistik-Funktionen verwenden. 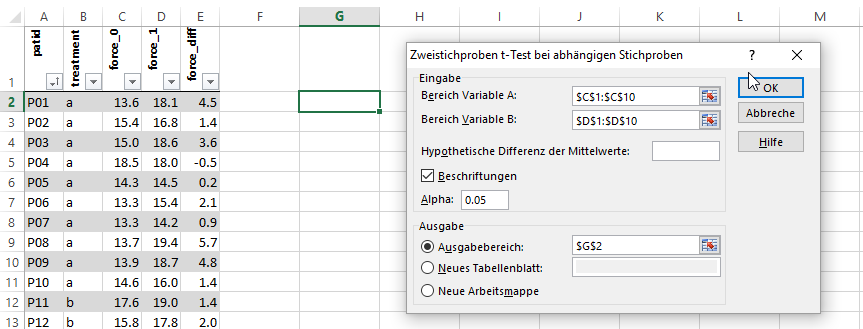
Leider gucken Apple-Benutzer dabei in die Röhre, ich konnte die Statistikfunktionen dort bisher nicht finden. Die hier beschriebene Methode ist zunächst etwas umständlicher, eignet sich aber sehr gut, wenn Sie viele Tests durchführen wollen, weil das Schema leicht kopiert werden kann und nur die Daten geändert werden. Und gleichzeitig lernen Sie etwas über Pivot-Tabellen, die für Sie auch zur Erstellung von anderer Tabellen sehr nützlich sind.
Hilfe, Pivot-Tabellen!
Für die Beschreibung Ihrer Ergebnisse und für die Tests benötigen Sie Mittelwerte, Standardabweichungen und die Anzahl der Daten, getrennt für die beiden Behandlungsgruppen a und b.
Das hier verwendeten Bilder beziehen sich auf Excel 2013; auch ältere Versionen können Pivot-Tabellen erzeugen, eventuell sieht das aber etwas anders aus, und Sie müssen im Internet Nachhilfe suchen.
- Fügen Sie eine Pivot-Tabelle ein; am besten gleich neben der Datentabelle. Die Tabelle wird an der Stelle eingefügt, wo der Mauscursor steht, beim Beispiel etwas in Feld
G1.

- Markieren Sie den Bereich Ihrer Datentabelle, einschließlich Überschriften, als “die zu analysierenden Daten”.

Rechts erscheint jetzt die Auswahlliste PivotTable-Felder. Ziehen Sie mit der Maus treatment in das Feld Spalten, Werte in das Feld Zeilen, und force_0 in das Feld Werte unten rechts.
Jetzt wird die Summe der Werte in der neu entstandenen Pivot-Tabelle dargestellt. Das wollen wir nicht, wir benötigen den Mittelwert. Klicken Sie mit der rechten Maustaste auf Summe von …, und dann auf Wertfeldeinstellungen

- Suchen Sie jetzt Mittelwert aus der Auswahlliste. Wenn Sie ganz nett sein wollen, können Sie auch unter Zahlenformat die Anzahl der Kommastellen begrenzen.

- Fügen Sie insgesamt die unten dargestellten 7 Felder hinzu: 3 Mittelwerte, 3 Standardabweichungen, und einmal die Anzahl Zahlen. Verwenden Sie immer Standardabweichung (Stichprobe), nie Standardabweichung (Grundgesamtheit).

- Und so sieht das Ergebnis aus: Alles perfekt zusammengestellt. Die Spalte Gesamtergebnis brauchen Sie nicht, aber alle anderen wohl.

Wie diese Daten in die Arbeit übernommen werden, steht weiter unten. Jetzt kommt zunächst die Statistik dran; leider müssen wir uns dazu von Pivot-Tabelle verabschieden, und zur Handarbeit greifen.
Statistische Tests
Wie die Tests und die Konfidenzintervalle berechnet werden, wird an Hand von Abbildungen der Formeln gezeigt.
Je nach Einstellung Ihres Rechners müssen Sie anstelle des Kommas in den Formeln ein Semikolon verwenden.
Für die Breite des Konfidenzintervalls benötigen Sie: * alpha: immer 0.05, das entspricht einem 95% Vertrauensintervall, das Sie bestimmen wollen * Standabw: die Standardabweichung aus der Pivot-Tabelle, hier im blau unterlegten Feld H8 * Umfang: Die Anzahl der Werte, also 10 für Behandlung a; steht im rot unterlegten Feld.

- Die untere Grenze des Konfidenzintervalls berechnen Sie aus dem Mittelwert minus der Breite des Konfidenzintervalls; also blau minus rot. Die obere Grenze als blau plus rot.

- Den p-Wert (Frage: verändert sich die Muskelkraft bei Behandlung a) bestimmen Sie mit einem gepaarten zweiseitigen t-Test. Blau und rot sind die Messwerte in C2:C11, D2:D11. 2 bedeutet “zweiseitiger Test, 1 heißt: gepaarte Daten.

- Frage 3: Nimmt die Muskelkraft bei einer der beiden Behandlungen mehr zu als bei der anderen? Das ist ein ungepaarter Test, der mit den Differenzen
force_diffin der blauen und der roten Gruppe arbeitet. Dass ein ungepaarter Test verwendet wird, zeigt der letzte Parameter (2) in der Formel an; verwenden Sie nicht die 3, deren Beschreibung auf den ersten Blick zutreffender klingt.

- Die Formeln für die Behandlung b sind analog aufgebaut wie die für a.

- Und hier sieht man das Ergebnis

Viele Zahlen - Was schreibe ich nun?
Hier ein Vorschlag, wie Sie dies in der Arbeit formulieren könnten. Einiges könnten Sie auch in der Tabelle lassen, aber manchmal ist ein ausformulierter Text einprägsamer. Schreiben Sie erst die Fakten, dann eine Interpretation. Sie dürfen in diesem Teil gerne Wiederholungen der Formulierungen bringen. Verzichten Sie in diesem Teil auf Wertungen, die kommen in der Diskussion, und dort sollten Sie etwas mehr literarische Ambitionen bei der Lesbarkeit entwickeln. Worte wie “leider”, “glücklicherweise nicht” sollten Sie aber nirgendwo verwenden.
Punktediagramm der Kraft bei Visite 1 gegen die Kraft bei der Eingangsvisite (Visite 0). Die beiden Behandlungsgruppen werden durch Farben unterschieden. Je weiter ein Punkt von der Winkelhalbierenden entfernt ist, desto größer ist die Verbesserung durch die Behandlung.
- Bei 10 Patienten in Behandlungsgruppe a wurde zu Beginn der Studie eine mittlere Hebekraft von 14.6 kp mit einer Standardabweichung von 1.6 kp gemessen. Nach der Behandlung ergab sich eine mittlere Hebekraft von 17 kp mit einer Standardabweichung von 1.9 kp.
- Bei 9 Patienten in Behandlungsgruppe b wurde zu Beginn der Studie eine mittlere Hebekraft von 15.5 kp mit einer Standardabweichung von 1.4 kp gemessen. Nach der Behandlung ergab sich eine mittlere Hebekraft von 16.2 kp mit einer Standardabweichung von 2.8 kp.
- Durch die Behandlung mit a erhöhte sich die Kraft im Mittel um 2.1 kp (95% Konfidenzintervall CI 0.9 bis 3.9 kp, p = 0.0057).
- Durch die Behandlung mit b erhöhte sich die Kraft im Mittel um 1.2 kp (CI -9 bis 3.9 kp, p = 0.26).
- Bei der Behandlung mit a war der Behandlungserfolg im Mittel 1.7 kp höher (CI
xxxbisyyykp, p = 0.054). - Mit Methode a wurde ein signifikanter Behandlungserfolg erzielt, mit Methode b nicht. Es konnte kein signifikanter Unterschied mit p <.05 zwischen den Methoden gefunden werden.
Der letzte Satz sollte ihnen sauer aufstoßen; ich habe die Daten absichtlich so gewählt, dass dieses Ergebnis herauskommt. Wenn sich bei Methode a ein signifikanter Effekt ergibt, also eine von Null verschiedene Verbesserung, bei Methode aber b nicht, dann muss doch ein signifikanter Unterschied zwischen den Methoden bestehen. Nein! Bei den vorher/nachher Vergleichen testen wir nämlich gegen Null, und das ist eine feste Zahl ohne Schwankung. Bei Frage 3, dem Vergleich zwischen zwei Methoden, testen wir zwei mit Fehler behaftete Größen gegeneinander. Der Mittelwert von a könnte kleiner sein, der von b größer - wir wissen es nicht. Merksatz, mit dem Sie bei der nächsten Party angeben können:
Der Unterschied zwischen signifikant und nicht signifikant ist nicht signifikant.
Vielleicht ist Ihnen auch xxx und yyy aufgefallen? Das war keine Vergesslichkeit, sondern meine Kapitulation vor Excel. Der p-Wert beim ungepaarten t-Test lässt sich mit Excel einfach berechnen, das Konfidenzintervall dagegen nicht. Ich wollte Ihnen die riesige Formel ersparen. Sie können die Spalten B und E in das die Zwischenablage legen, diese dann in Ihre Installation von wctest einfügen und erhalten dann für xxx = -0.05 und yyy = 3.56. Die Methode ist nicht perfekt, weil wctest den Wilcoxon-Test verwendet, die Excel-Methode dagegen den t-Test. Aber good enough for your professor.
Des Menne letzter Seufzer
Wenn Sie es bis hierhin geschafft haben, Gratulation. Trotzdem wette ich, dass Sie zu faul waren, Kommastellen auszublenden, und dass Sie Zahlen wie 3.141589383 auf dem Bildschirm sehen. Es geht doch auch so… Nein, Sie lernen nie, wie man Zahlen durch anschauen bewerten kann, wenn Sie den üblichen Salat vor sich haben.

Wer ohne dies zu lesen die Kommastellen von vorneherein ausgeblendet hat und das glaubhaft beschwört, bekommt von mir beim nächsten Meeting eine Tafel Quadratisch-Gut1.
Fußnoten
Dieser Text war für eine Klasse bestimmt. Andere bekommen virtuelle Tafeln↩︎